Well, it was comfortable while it lasted.
I’m referring to the widespread attitude towards artificial intelligence in law, to the effect that we don’t have to do anything about it yet because the technology has yet to prove itself. Some day, maybe, and we’ll worry about it then. Maybe.
Time’s up.
Across my desk this week came a just-released report from Blue Hill, the Boston-based research and advisory firm specializing in enterprise technology: Their particular foci include AI, cloud, neural science and machine learning, mobile, and security technologies, and perhaps not surprisingly they conduct research and write reports on legal technology on a fairly regular basis.
The report that hit my desk is ROSS Intelligence and Artificial Intelligence in Legal Research, which addresses head-on the psychological, cultural, and quasi-tribal disconnect between the believers and the deniers when it comes to legal AI. From the executive summary:
The growing availability and practicality of artificial intelligence (AI) technologies such as machine learning and Natural Language processing within the legal sector has created a new class of tools that assist legal analysis within activities like legal research, discovery and document review, and contract review. Often, the promised value of these tools is significant, while lingering cultural reluctance and skepticism within the legal profession can lead to hyperbolic reactions to so-called “robot lawyers,” both positive and negative.
To confront this chasm, Blue Hill did what any serious researcher would do: Set up, conducted, and reported the results of an experiment comparing AI-enabled tools to conventional ones on about as level a playing field as it’s possible to imagine.
Specifically, they compared the ROSS Intelligence tool to Lexis and Westlaw, using both Boolean and natural language search. (“Boolean” is basically the familiar keyword approach, allowing you to specify required words, impermissible words, and combinations using “and” and “or.” Natural language is what you’re reading.)
While I’m not formally trained in objective research protocols, their setup of the research struck me as scrupulous:
- Sixteen experienced legal research professionals were randomly assigned into four groups of four apiece.
- Each received a standard set of seven questions designed to emulate real-world queries practicing lawyers would pose.
- For consistency, the subject matter was limited to US federal bankruptcy law.
- Each of the sixteen was asked to research and provide a written answer to the legal question posed, with in a two-hour time limit.
- Although experienced in legal research generally, none of the sixteen had more than passing acquaintance with bankruptcy law.
- And each was assigned to a tool (Lexis, Westlaw, or ROSS) that they were largely unfamiliar with. (Westlaw mavens were sicced on Lexis and vice versa; presumably none were familiar with ROSS out of the box.)
To evaluate the results, Blue Hill measured the time each spent (a) researching; and (b) writing their responses. They also compared:
- Information retrieval quality: What portion of the total results retrieved were drawn from truly relevant sources, what portion of all the items presented were themselves relevant, and were the most relevant placed at the top of the list.
- User satisfaction: How easy was the tool to use and how much confidence did the researcher have in the results.
- Efficiency: Time it took to arrive at a satisfactory answer.
Finally, for simplicity and ease of comparison in evaluating quality and relevance of the search tools, Blue Hill took into account only the first 20 results produced in response to each research query.
Their analysis looked at (a) information retrieval accuracy; (b) user satisfaction; and (c) efficiency.
Recall our three contestants are the new entrant ROSS, the challenger (in Boolean and natural language incarnations) and the composite Lexis/Westlaw incumbent and reigning champions, in Boolean and natural language flavors.
With that lengthy stage-setting, shall we see what they learned?
(A) Information retrieval accuracy
The criteria were percentage of relevant authorities retrieved (0—100%), percentage of retrieved results that were relevant (0—100%), and a measurement of how closely the prioritization of results matched the ideal using the standard scale for this, called the “Normalized Discounted Cumulative Gain,” or NDCG to you (0.0—1.0, by convention).
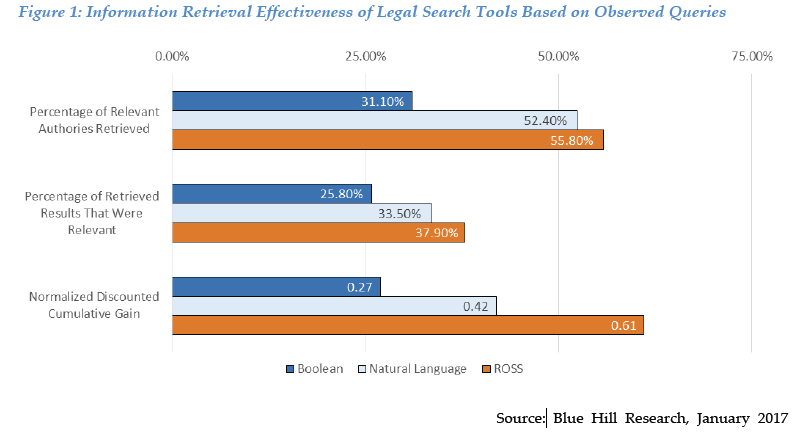
Boolean (in dark blue) brings up the rear here, across the board. It’s the least thorough, the least relevant, and most poorly ranked. Less than one in three of the responsive authorities was retrieved, barely one in four was relevant, and natural language and ROSS NDCG scores were 46% and 128% higher, respectively. Natural language (light bluish-grey) was second across the board, and ROSS (orange) won handily: It produced more relevant results with less noise and concentrated them highly within the first results the user sees.
(B) User satisfaction, shall we?
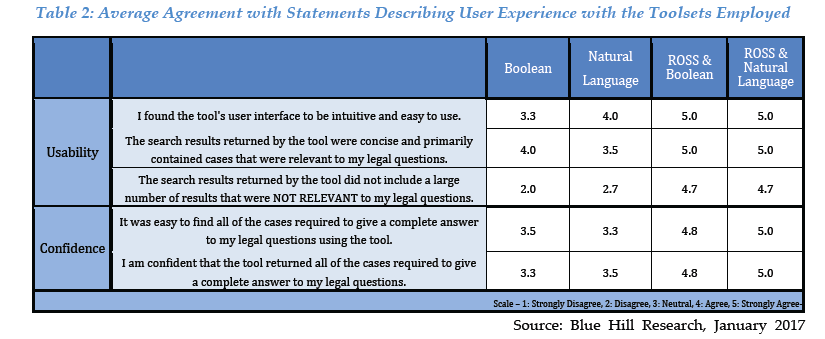
Less legible at reduced magnification, but here are the highlights.
Researchers were asked to score their agrement/disagreement with each subjective experience question using the familiar 5-point “Likert” scale, where 1 = strong disagreement and 5 = strong agreement. Again, across the board, ROSS won with user’s satisfaction and confidence, by one full point or more. Indeed, ROSS scored a perfect 5.0 on every measure but one (“results did not include a large number that weren’t relevant”) where ROSS scored 4.7 but Boolean scored 2.0 and natural language 2.7.
Anecdotally, Blue Hill notes that participants in the ROSS group used ROSS more and more as they progressed through the questions, confirming satisfaction and confidence.
(C) Efficiency
The two-hour limit proved no obstacle, but research took 30% less time with ROSS than with Boolean and 22% less than with natural language (36 1/2 minutes vs. 52 and 47). Although Blue Hill also measured writing time, because it varied greatly among assessment groups and among individuals, they concluded that no “discernable pattern” emerged, so drew no conclusions on that score. But here is the efficiency chart:
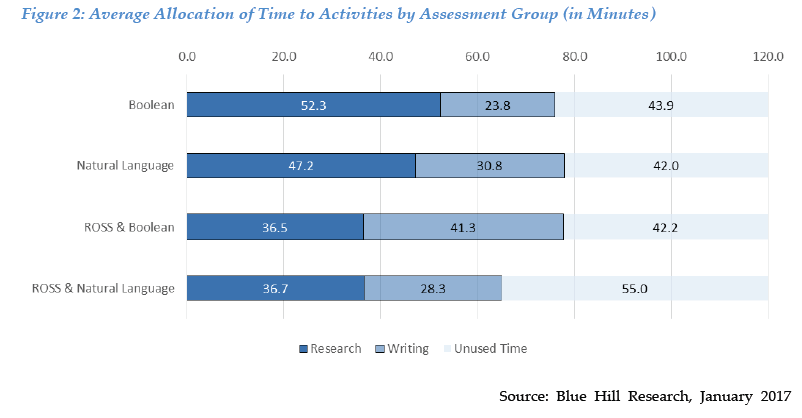
There’s no question research with ROSS is more efficient: Only you can answer whether that’s good or bad (just don’t ask your clients which they prefer; you might not get the answer you want).
Our Blue Hill friends are king, and thorough, enough to present an entire table quantifying the potential time savings—and revenue in billable time made available by completing the research faster—should you care to examine it at home. It assumes greater efficiency reduces writeoffs, so the time saved is truly available for incremental billing and collecting. If you disagree, they politely display the marginal revenue at 10%, 25%, 33.3%, 50%, 75%, and 100% conversion ratios.
I will cite only the most conservative number they provide, which goes to the ROI of investing in AI.
Assuming:
- A cost per AI-enabled seat of $2,400 to $4,800 per year;
- A 22% (natural language) or 30% (Boolean) time savings by using ROSS, and
- A billing rate of $320/hour
Then:
- The return (marginal revenue – cost of AI) ranges from $506/year to $3,787/year at a 10% conversion rate of time saved, for an ROI of 10.5—158%.
- At a conversion rate of 100%, the ROI spikes to 1,005%—2,478%.
As I said, I’ll let you run the numbers at home.
Our assumption until now has been that it’s early days for AI and so we could ignore it. We were half right. It’s still very early days for AI. Think you can still ignore it?
If after all this you don’t even want to take a closer look, I have a question: Are you still writing by candlelight or have you advanced to gas lamps? Because you’re surely not interested in electricity.



A reader who prefers anonymity (but who knows to a fare-thee-well whereof he speaks) wrote me as follows, verbatim:
I would be most interested in other knowledgeable comments.